Caratteri a larghezza piena e a mezza larghezza
Nell’ambito dell’informatica CJK (Cinese, Giapponese e Coreano), i caratteri grafici sono tradizionalmente classificati come caratteri a larghezza piena o a mezza larghezza. Nel contesto dei tipi di carattere a larghezza fissa, un glifo a mezza larghezza occupa la metà dello spazio orizzontale rispetto a un simbolo a larghezza piena, il che spiega la sua denominazione.
Nell’epoca dei terminali e della rappresentazione informatica in modalità testuale, i caratteri erano normalmente disposti all’interno di una griglia, spesso composta di 80 colonne su 24 o 25 righe. Ogni carattere veniva visualizzato sotto forma di una piccola matrice di punti, tipicamente della dimensione di circa 8 pixel, e l’adozione di un SBCS (set di caratteri a byte singolo) era generalmente invalsa per la codifica dei caratteri propri delle lingue occidentali.
Con l’avvento dello standard Unicode, se un dato grafema può essere rappresentato come carattere a larghezza piena o come carattere a mezza larghezza, quel simbolo si definisce dotato contemporaneamente di una forma a larghezza piena e di una forma a mezza larghezza.
Forme a mezza larghezza e a larghezza piena è il nome del blocco Unicode U+FF00–FFEF, che costituisce l’ultima sezione del Piano di base multilinguistico e che non comprende il breve blocco dei Caratteri speciali, compresi nell’intervallo U+FFF0–FFFF.
Fonte: Wikipedia
Perché utilizzarli in AncientGreek? ^
Legacy Ancient Greek encodings (such as Beta Code and SPIonic) use ASCII characters (Lettere occidentali, punctuation marks etc.) to represent AncientGreek text. Furthermore, SPIonic uses numbers (0-9) to represent AncientGreek punctuation marks. This means that documents written in any of these legacy Ancient Greek encodings simply cannot contain English text (or any text using ASCII characters), because that would be interpreted as Ancient Greek text.
The problem is much more intense when trying to convert Unicode text to any of these legacy Ancient Greek encodings, since ASCII character usually is present (for example the Editor's name). Converting such text would result to irrecoverably destroying that ASCII written English text.
L’unica soluzione consiste quindi nel “camuffare” i caratteri ASCII (il testo in alfabeto occidentale), così da evitare che una qualsiasi conversione li comprenda; ed è proprio in questi casi che entrano in gioco i caratteri a larghezza piena e a mezza larghezza: convertire i caratteri ASCII (il testo in alfabeto occidentale) in caratteri a larghezza piena o a mezza larghezza prima della conversione del testo in greco antico in Beta Code o SPIonic (o una qualsiasi delle altre codifiche obsolete) conserverà quelle stringhe in una forma ancora leggibile, come mostrato nell’immagine seguente.
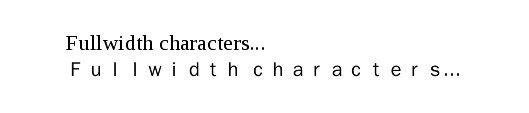
La prima riga è scritta in caratteri normali (ASCII), mentre la seconda è il risultato di una conversione in caratteri a larghezza piena.
Quali caratteri utilizzare ^
Quando un testo viene convertito in caratteri a larghezza piena, LibreOffice / OpenOffice è programmato per tentare di trovare un tipo di carattere che possa rappresentare i glifi utilizzati. La ricerca ha esito positivo o negativo in rapporto ai tipi di carattere installati e disponibili all’uso.
Se la ricerca di un tipo di carattere appropriato va a buon fine, si otterrà allora un risultato simile a quello rappresentato nell’immagine precedente; se fallisce, si otterrà invece un risultato simile a questo:

In tal caso, occorrerà installare un tipo di caratteri appropriato.
Per esempio, su un sistema dotato di una versione Debian Linux nativa, non è disponibile alcun tipo di carattere appropriato per impostazione predefinita. Una ricerca per “CJK” e “font” offre come risultato il pacchetto chiamato “ttf-wqy-zenhei”: dopo averlo installato e aver riavviato LibreOffice / OpenOffice, il problema si può dire risolto.
La tabella seguente mostra i risultati delle mie ricerche a proposito della disponibilità dei tipi di carattere CJK sui sistemi operativi supportati da AncientGreek.
| Sistema operativo | Nome del tipo di carattere | Funzionamento |
|---|---|---|
| Windows XP SP3 | Arial Unicode MS | Installazione manuale |
| Windows 7-8-8.1/10 | SimSun/Source Han Sans CN Regular | Automatico |
| Debian Linux | WenQuanYi Zen Hei | Installazione manuale |
| Debian sid | AR PL SungtiL GB | Installazione manuale |
| Mac OS | Arial Unicode MS | Automatico |
Come funziona ^
Come chiarito in precedenza, i caratteri a larghezza piena si dimostrano pratici solo in caso di necessità di conversione di un testo Unicode in un testo greco dotato di una codifica obsoleta (Beta Code, SPIonic, ecc.).
The text to be converted is checked for ASCII characters (English text) and if found it will first be converted to fullwidth characters, and then the legacy Ancient Greek encoding will be performed.
In caso di conversione del testo da una codifica obsoleta a Unicode, avviene invece una conversione aggiuntiva in seguito a quella principale: tutti i caratteri a larghezza piena vengono automaticamente riconvertiti in Unicode.
La finestra di dialogo Conversione dei caratteri a larghezza piena e a mezza larghezza ^
AncientGreek fornisce uno strumento utile a convertire manualmente i caratteri ASCII in caratteri a mezza larghezza o a larghezza piena (e viceversa) attraverso la relativa finestra di dialogo (mostrata sotto), a cui si può accedere da “Menu di AncientGreek / Codifiche obsolete / Caratteri a mezza larghezza / larghezza piena” o facendo clic sull’icona  presente nella barra degli strumenti secondaria.
presente nella barra degli strumenti secondaria.
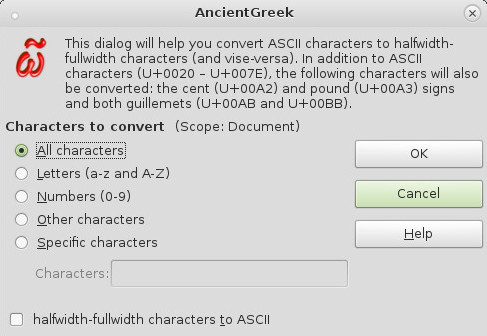
La finestra di dialogo su Debian Linux
Le opzioni disponibili sono:
- All characters
All the characters handled by this function: ASCII characters (U+0020 – U+007E), that is letters and numbers, quotation marks and brackets etc., plus the cent (¢ - U+00A2) and pound (£ - U+00A3) signs and both guillemots (« - U+00AB and » - U+00BB). - Lettere (a-z e A-Z)
- Numeri (0-9)
- Altri caratteri
Tutti i caratteri gestiti da questa funzione, tranne le lettere e i numeri. - Caratteri specifici
Attivando questa casella, il campo di testo “Caratteri” diventa attivo, consentendo così l’inserimento di qualunque carattere. Se la conversione dei caratteri digitati qui non risulta possibile, il carattere verrà ignorato.
Attivando la casella “Da caratteri a mezza larghezza o larghezza piena in caratteri ASCII”, verrà eseguita una conversione inversa. Questa funzione in realtà è superflua, poiché qualunque conversione da codifica obsoleta in Unicode eseguirà l’azione suddetta per impostazione predefinita.