WinGreek Encoding
WinGreek is "a system for using Greek and Hebrew fonts in Windows. It is comprised of a set of fonts and some utilities". The fonts provided are "Greek Regular" and "GreekWG Regular". Text written in WinGreek is called WinGreek Encoded.
"Greek Regular" comes in two editions; the original 1993 edition and the 2000 edition, which is somewhat different from its predecessor and codes more letters as well.
Since the WinGreek system is proprietary S/W, these fonts cannot be published here, but can easily be obtained form WinGreek site or the internet.
AncientGreek WinGreek conversion Macros ^
I suggest saving your work before running either of these macros on a document (no text selection), so that reverting (Menu File / Reload) to it is possible, as Undoing may not be of much help, since a letter by letter substitution will take place resulting in way too many undo steps.
If any of these macros are executed without selecting any text, a warning message similar to the one shown in the following picture will appear.
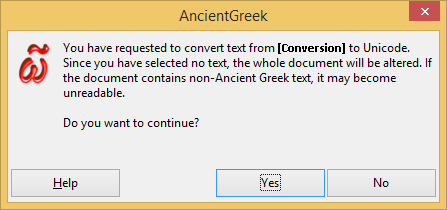
Warning message on Windows 8.1
WinGreek font detection ^
Since WinGreek conversion depends entirely on the font used (or will be used), AncientGreek implementation has to take it into account too. So, when a WinGreek conversion starts, the document (or selection) is parsed character by character and fonts found are encountered for. Possible results are to find:
- Greek font only
- This means that either a 1993 or a 2000 font edition based conversion can be performed. If the preferred font edition has already been set (WinGreek configuration), then it will be used. Otherwise, the font selection window will be displayed so that the user can choose the font to be used.
- GreekWG font only
- A GreekWG font based conversion will be performed.
- WinGreek and non-WinGreek font
- The user will be asked whether the conversion should continue or not, using the following dialog.
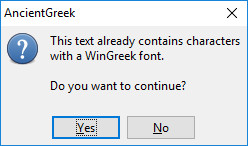
- If the answer is positive, the font selection dialog will be presented to the user. The font proposed will be:
- "Greek font (ed. 1993)", if the font found is "Greek" and the font's edition is set to 1993 (WinGreek configuration).
- "Greek font (ed. 2000)", if the font found is "Greek" and the font's edition is set to 2000 (WinGreek configuration).
- "Greek font (ed. 2000)", if the font found is "Greek" and the font's edition is not set (WinGreek configuration).
- "GreekWG font", if the font found is "GreekWG".
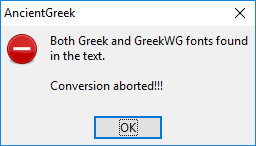
- Both Greek and GreekWG fonts
- AncientGreek will not perform any conversion in this case. It will just display the following message and stop.
- No WinGreek fonts
- AncientGreek will display the font selection dialog so that the user can choose the font to be used.
The WinGreek font detection dialog ^
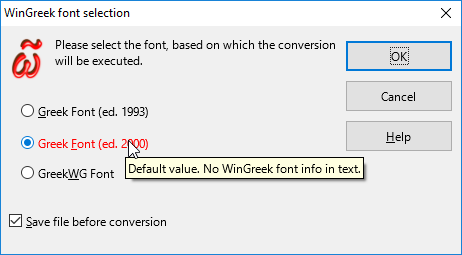
The font selection dialog on Windows 10
The "font selection dialog" will be displayed:
- When the WinGreek configuration option "Font selection always permitted" is set (checked).
- When the the WinGreek configuration has not been performed.
- This means that AncientGreek does not know what kind of conversion to execute (actually what font the conversion will be based on).
- When both WinGreek and non-WinGreek characters are found in the text.
Suggested font
The "font selection dialog" will always suggest a font to use for the conversion. The color of the suggested font will be:
Blue: A default value is suggested. This may mean that the WinGreek configuration has not been performed.
Red: The font suggested has been found in the text in question (document or selection). If non-WinGreek font(s) exist also, the conversion may result in a corrupt output.
If AncientGreek suggests a font which might lead to corrupt conversion results, or a default arbitrary font is suggested, and the "Save file before conversion" general option has not been set, the dialog will include and enable this option, as shown in the image above.
Defaults indication
If the WinGreek configuration has already been performed, default fonts will be indicated as follows:
- Greek font selection will be in bold characters.
- WinGreek font selection will be in underlined characters.
WinGreek Macros ^
• WinGreekToUnicode Macro
This macro converts text written in WinGreek to Unicode (normal text that can be edited in LibreOffice / OpenOffice).
• UnicodeToWinGreek Macro
This macro converts text written in Unicode (normal text edited in LibreOffice / OpenOffice) to WinGreek.
Several characters will be converted to fullwidth/halfwidth characters before starting the actual conversion to WinGreek. These characters include "$", "#", "%", "«", "»" etc. which are used by WinGreek to represent Ancient Greek letters. These characters will be converted to their original value when converting back to Unicode.
The following table shows the characters substitution that takes place when converting Unicode text to WinGreek. All substitute characters are fullwidth/halhwidth characters, unless otherwise noted.
| Original character | Substitute character | Original character | Substitute character | |
|---|---|---|---|---|
| En Dash (– U+2013) | - (U+FF0D) | Hash Sign (# U+0023) | # (U+FF03) | |
| Em Dash (— U+2014) | ― (U+2015) * | Dollar Sign ($ U+0024) | $ (U+FF04) | |
| Quotation Mark (" U+0022) | " (U+FF02) | Percent Sign (% U+0025) | % (U+FF05) | |
| Left Single Quotation Mark (‘ U+2018) | ʻ (U+02BB) * | Ampersand (& U+0026) | & (U+FF06) | |
| Apostroph (Right Single Quotation Mark) (’ U+2019) | ʼ (U+02BC) * | Colon (: U+003A) | : (U+FF1A) | |
| Left Low Single Quotation Mark (‚ U+201A) | ❟ (U+275F) * | Commercial At (@ U+0040) | @ (U+FF20) | |
| Right High Double Quotation Mark (“ U+201C) | 〝 (U+301D) * | Cent Sign (¢ U+00A2) | ¢ (U+FFE0) | |
| Right Double Quotation Mark (” U+201D) | ″ (U+2033) * | Pound Sign (£ U+00A3) | £ (U+FFE1) | |
| Left Low Double Quotation Mark („ U+201E) | 〟 (U+301F) * | Broken Bar (¦ U+00A6) | ¦ (U+FFE4) | |
| Left Double Angle Bracket (« U+00AB) | 《 (U+300A) * | Slash (/ U+002F) | / (U+FF0F) | |
| Right Double Angle Bracket (» U+00BB) | 》 (U+300B) * | Backslash (\ U+005C) | \ (U+FF3C) | |
| Exclamation Mark (! U+0021) | ! (U+FF01) | Bullet (• U+2022) | ・ (U+FF65) | |
| Plus Sign (+ U+002B) | + (U+FF0B) | Circumflex Accent (^ U+005E) | ^ (U+FF3E) | |
| Plus-Minus Sign (± U+00B1) | +/- (U+FF0B U+FF0F U+FF0D) |
* Non fullwidth/halhwidth character.
Furthermore, several characters are missing from WinGreek Encoding altogether, so they have to be converted to "equivalent" characters before the actual conversion to WinGreek is performed. These characters are shown in the following table:
| Missing character | Substitute character | Missing character | Substitute character | |
|---|---|---|---|---|
| ᾂ (U+1F82) | ἂ (U+1F02) | Ῠ (U+1FE8) | Υ (U+03A5) | |
| Ᾰ (U+1FB8) | Α (U+0391) | Ῡ (U+1FE9) | Υ (U+03A5) | |
| Ᾱ (U+1FB9) | Α (U+0391) | ῠ (U+1FE0) | υ (U+03C5) | |
| ᾰ (U+1FB0) | α (U+03B1) | ῡ (U+1FE1)* | υ (U+03C5) | |
| ᾱ (U+1FB1)* | α (U+03B1) | Ϊ (U+03AA) | Ι (U+0399) | |
| ῐ (U+1FD0) | ι (U+03B9) | Ϋ (U+03AB) | Υ (U+03A5) | |
| ῑ (U+1FD1)* | ι (U+03B9) | ῗ (U+1FD7) | ϊ (U+03CA) | |
| Ῐ (U+1FD8) | Ι (U+0399) | ῧ (U+1FE7) | ϋ (U+03CD) | |
| Ῑ (U+1FD9) | Ι (U+0399) |
* Valid for Greek ed. 1993 only.
Duplicate characters ^
Greek ed. 2000 contains several duplicate characters, shown in the following table:
| Unicode character | First form | Second form | Unicode character | First form | Second form | |
|---|---|---|---|---|---|---|
| έ (U+03AD) | U+009A | U+0161 | ὶ (U+1F76) | U+0088 | U+02C6 | |
| ἐ (U+1F10) | U+0099 | U+2122 | ἲ (U+1F32) | U+008A | U+0160 | |
| ἑ (U+1F11) | U+0098 | U+02DC | ἳ (U+1F33) | U+0089 | U+2030 | |
| ἒ (U+1F12) | U+009F | U+0178 | ἴ (U+1F34) | U+0087 | U+2021 | |
| ἓ (U+1F13) | U+009E | U+017E | ἵ (U+1F35) | U+0086 | U+2020 | |
| ἔ (U+1F14) | U+009C | U+0153 | ἷ (U+1F37) | U+008C | U+0152 | |
| ἕ (U+1F15) | U+009B | U+203A | ῖ (U+1FD6) | U+008B | U+2039 | |
| ί (U+03AF) | U+0085 | U+2026 | ῟ (U+1FDF) | U+0091 | U+2018 | |
| ϊ (U+03CA) | U+017D | U+008E | ῏ (U+1FCF) | U+0092 | U+2019 | |
| ΐ (U+0390) | U+010C | U+008F | ῞ (U+1FDE) | U+0093 | U+201C | |
| ῒ (U+1FD2) | U+010D | U+0090 | ῎ (U+1FCE) | U+0094 | U+201D | |
| ἰ (U+1F30) | U+0084 | U+201E | ῝ (U+1FDD) | U+0095 | U+2022 | |
| ἱ (U+1F31) | U+0083 | U+0192 | ῍ (U+1FCD) | U+0096 | U+2013 |
AncientGreek will correctly convert these characters to Unicode, but will use only the "Second form" set when concerting text to WinGreek.
Using fullwidth characters ^
If the document (or selection) contains ASCII characters (English text), they will automatically be converted to the "fullwidth / halfwidth" characters, when text conversion from Unicode to WinGreek is performed.
WinGreek implementation ^
AncientGreek fully implements the encoding as shown in the following table.
Note: ASCII control characters are displayed using the terms defined at The Unicode Consortium Specification v. 7, (in bold green color) followed by their Unicode code.
The following indications mean:
*Greek font ed. 2000 duplicate character
1valid for Greek font ed. 1993 only
2valid for Greek font ed. 2000 only
3valid for GreekWG font only
| Greek Letter | ASCII character (Lowercase) | ASCII character (Uppercase) | Greek Letter | ASCII character (Lowercase) | ASCII character (Uppercase) |
|---|---|---|---|---|---|
| Alpha | a | A | Nu | n | N |
| Beta | b | B | Xi | x | X |
| Gamma | g | G | Omicron | o | O |
| Delta | d | D | Pi | p | P |
| Epsilon | e | E | Rho | r | R |
| Zeta | z | Z | Sigma | s | S |
| Eta | h | H | Tau | t | T |
| Theta | q | Q | Upsilon | u | U |
| Iota | i | I | Phi | f | F |
| Kappa | k | K | Chi | c | C |
| Lambda | l | L | Psi | y | Y |
| Mu | m | M | Omega | w | W |
| Sampi | " (U+0022) | Digamma | # | ||
| Final sigma | j | Stigma | $ | & | |
| Rho with Rough Breathing | ∙ (U+2019)1 · (U+00B7)2 |
Rho with Smooth Breathing | ¸ (U+00B8) | ||
| Archaic Koppa | % | South West Arrow (↙) | ! | ||
| Stand-alone Diacritics | |||||
| Symbol | ASCII Character | Symbol | ASCII Character | Symbol | ASCII Character |
| Smooth breathing | ' | Rough breathing | ` | Iota subscript | Ä |
| Acute | / | Grave | \ | Circumflex | ^ |
| Smooth breathing with Acute* | ” | Smooth breathing with Grave* | – | Smooth breathing with Circumflex* | ’ |
| Rough breathing with Acute* | “ | Rough breathing with Grave* | • | Rough breathing with Circumflex* | ‘ |
| Diaeresis with acute | —1 EPA (U+0097)2 |
Diaeresis with grave | NBSP (U+00A0) | Iota subscript | Ä |
| Macron | XXX (U+0080)2 | ||||
| Small Greek vowels with diacritics | |||||
| Symbol | ASCII Character | Symbol | ASCII Character | Symbol | ASCII Character |
| Alpha with smooth breathing | ¢ | Alpha with rough breathing | ¡ | Alpha with iota subscript | & |
| Alpha with acute | £ | Alpha with grave | ¦ | Alpha with circumflex | © |
| Alpha with acute and iota subscript | ® | Alpha with grave and iota subscript | ± | Alpha with circumflex and iota subscript | ´ |
| Alpha with smooth breathing and acute | ¥ | Alpha with smooth breathing and grave | ¨ | Alpha with smooth breathing and circumflex | « |
| Alpha with rough breathing and acute | ¤ | Alpha with rough breathing and grave | § | Alpha with rough breathing and circumflex | ª |
| Alpha with smooth breathing and iota subscript | −1 SHY (U+00AD)23 |
Alpha with rough breathing and iota subscript | ¬ | Alpha with macron | BPH (U+0082)2 |
| Alpha with smooth breathing, acute and iota subscript | ° | Alpha with smooth breathing, grave and iota subscript | ³ | Alpha with smooth breathing, circumflex and iota subscript | ¶ |
| Alpha with rough breathing, acute and iota subscript | ¯ | Alpha with rough breathing, grave and iota subscript | ² | Alpha with rough breathing, circumflex and iota subscript | µ |
| Epsilon with smooth breathing* | ™ | Epsilon with rough breathing* | ˜ | ||
| Epsilon with acute* | š | Epsilon with grave | OSC (U+009D) | Epsilon with circumflex | ü |
| Epsilon with smooth breathing and acute* | œ | Epsilon with smooth breathing and grave* | Ÿ | ||
| Epsilon with rough breathing and acute* | › | Epsilon with rough breathing and grave* | ž | ||
| Eta with smooth breathing | ¸ | Eta with rough breathing | ¹ | Eta with iota subscript | Ä |
| Eta with acute | » | Eta with grave | ¾ | Eta with circumflex | Á |
| Eta with acute and iota subscript | Ç | Eta with grave and iota subscript | Ê | Eta with circumflex and iota subscript | Í |
| Eta with smooth breathing and acute | Û | Eta with smooth breathing and grave | À | Eta with smooth breathing and circumflex | Ã |
| Eta with rough breathing and acute | ¼ | Eta with rough breathing and grave | ¿ | Eta with rough breathing and circumflex | Â |
| Eta with smooth breathing and iota subscript | Æ | Eta with rough breathing and iota subscript | Å | ||
| Eta with smooth breathing, acute and iota subscript | É | Eta with smooth breathing, grave and iota subscript | Ì | Eta with smooth breathing, circumflex and iota subscript | Ï |
| Eta with rough breathing, acute and iota subscript | È | Eta with rough breathing, grave and iota subscript | Ë | Eta with rough breathing, circumflex and iota subscript | Î |
| Iota with smooth breathing* | „ | Iota with rough breathing* | ƒ | Iota with macron | þ23 |
| Iota with acute* | … | Iota with grave* | ˆ | Iota with circumflex* | ‹ |
| Iota with smooth breathing and acute* | ‡ | Iota with smooth breathing and grave* | Š | Iota with smooth breathing and circumflex* | RI (U+008D) |
| Iota with rough breathing and acute* | † | Iota with rough breathing and grave* | ‰ | Iota with rough breathing and circumflex* | Œ |
| Iota with diaeresis and acute* | SS3 (U+008F) | Iota with diaeresis and grave* | DCS (U+0090) | Iota with diaeresis* | SS2 (U+008E) |
| Omicron with smooth breathing | Ñ | Omicron with rough breathing | Ð | ||
| Omicron with acute | Ò | Omicron with grave | Õ | Omicron with circumflex | ý |
| Omicron with smooth breathing and acute | Ô | Omicron with smooth breathing and grave | × | ||
| Omicron with rough breathing and acute | Ó | Omicron with rough breathing and grave | Ö | ||
| Upsilon with smooth breathing | Ù | Upsilon with rough breathing | Ø | Upsilon with macron | ÿ23 |
| Upsilon with acute | Ú | Upsilon with grave | Ý | Upsilon with circumflex | à |
| Upsilon with smooth breathing and acute | Ü | Upsilon with smooth breathing and grave | ß | Upsilon with smooth breathing and circumflex | â |
| Upsilon with rough breathing and acute | Û | Upsilon with rough breathing and grave | Þ | Upsilon with rough breathing and circumflex | á |
| Upsilon with diaeresis and acute | ä | Upsilon with diaeresis and grave | å | Upsilon with diaeresis | ã |
| Omega with smooth breathing | ç | Omega with rough breathing | æ | Omega with iota subscript | J |
| Omega with acute | è | Omega with grave | ë | Omega with circumflex | î |
| Omega with acute and iota subscript | ó | Omega with grave and iota subscript | ö | Omega with circumflex and iota subscript | ù |
| Omega with smooth breathing and acute | ê | Omega with smooth breathing and grave | í | Omega with smooth breathing and circumflex | ð |
| Omega with rough breathing and acute | é | Omega with rough breathing and grave | ì | Omega with rough breathing and circumflex | ï |
| Omega with smooth breathing and iota subscript | ò | Omega with rough breathing and iota subscript | ñ | ||
| Omega with smooth breathing, acute and iota subscript | õ | Omega with smooth breathing, grave and iota subscript | ø | Omega with smooth breathing, circumflex and iota subscript | û |
| Omega with rough breathing, acute and iota subscript | ô | Omega with rough breathing, grave and iota subscript | ÷ | Omega with rough breathing, circumflex and iota subscript | ú |
Diacritics ^
- On uppercase letters these are keyed in the order:
- (1) breathing, (2) letter
- (1) accent, (2) letter
- (1) breathing & accent, (2) letter
- Iota subscript is inserted using an i (U+0069) character following any of the previous combinations