Fullwidth - Halfwidth Characters
In CJK (Chinese, Japanese and Korean) computing, graphic characters are traditionally classed into fullwidth and halfwidth characters. With fixed-width fonts, a halfwidth character occupies half the width of a fullwidth character, hence the name.
In the days of computer terminals and text mode computing, characters were normally laid out in a grid, often 80 columns by 24 or 25 lines. Each character was displayed as a small dot matrix, often about 8 pixels wide, and an SBCS (single byte character set) was generally used to encode characters of western languages.
In Unicode, if a certain grapheme can be represented as either a fullwidth character or a halfwidth character, it is said to have both a fullwidth form and a halfwidth form.
Halfwidth and Fullwidth Forms is the name of Unicode block U+FF00–FFEF, the last of the Basic Multilingual Plane excepting the short Specials block at U+FFF0–FFFF.
Source: Wikipedia
Why use them in AncientGreek? ^
Legacy Ancient Greek encodings (such as Beta Code and SPIonic) use ASCII characters (English letters, punctuation marks etc.) to represent AncientGreek text. Furthermore, SPIonic uses numbers (0-9) to represent AncientGreek punctuation marks. This means that documents written in any of these legacy Ancient Greek encodings simply cannot contain English text (or any text using ASCII characters), because that would be interpreted as Ancient Greek text.
The problem is much more intense when trying to convert Unicode text to any of these legacy Ancient Greek encodings, since ASCII character usually is present (for example the Editor's name). Converting such text would result to irrecoverably destroying that ASCII written English text.
The only solution is to "disguise" ASCII characters (English text) so that any conversion will not affect them. This is where fullwidth and halfwidth characters come in. Coverting ASCII characters (English text) to fullwidth / halfwidth characters before converting Ancient Greek text to Beta Code or SPIonic (or any other legacy encoding), would preserve them in a state that's still readable as you can see on the following picture.
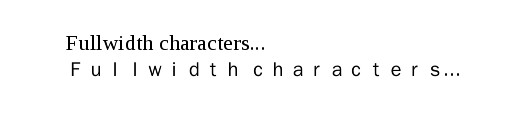
The first line is written in normal (ASCII) characters and the second one is converted to fullwidth characters.
What fonts to use ^
When text is converted to fullwidth characters, LibreOffice / OpenOffice tries to find a font that can display the code-points inserted. Whether it succeeds or not depends on the fonts installed and made available to it.
If it does succeeds, then one would get something like the picture above. If it does not, then one would get something like this:

If this is the case, one has to install a suitable font.
For example, in a freshly installed Debian Linux box, no suitable font is available by default. A search for "CJK" and "font" returns the package called "ttf-wqy-zenhei". After installing it and restarting LibreOffice / OpenOffice, the problem is resolved.
The following table shows what I have found out about CJK fonts availability on the Operating Systems supported by AncientGreek.
| O.S. | Font Name | Works |
|---|---|---|
| Windows XP SP3 | Arial Unicode MS | Manual install |
| Windows 7-8-8.1/10 | SimSun/Source Han Sans CN Regular | Automatically |
| Debian Linux | WenQuanYi Zen Hei | Manual install |
| Debian sid | AR PL SungtiL GB | Manual install |
| Mac OS | Arial Unicode MS | Automatically |
How it works ^
As already mentioned before, fullwidth characters come handy only when converting Unicode text to a legacy AncientGreek encoding (Beta Code, SPIonic, etc.).
The text to be converted is checked for ASCII characters (English text) and if found it will first be converted to fullwidth characters, and then the legacy Ancient Greek encoding will be performed.
When converting legacy encoded text to Unicode, an extra conversion occurs after the main conversion; all fullwidth characters are automatically converted back to Unicode.
Fullwidth - Halfwidth Characters conversion dialog ^
AncientGreek provides a way to manually convert ASCII characters to halfwidth-fullwidth characters (and vise-versa), through its relevant dialog (shown bellow), which can be opened from the "AncientGreek Menu / Legacy encodings / Half/Fullwidth Characters" or by clicking the  icon on the secondary toolbar.
icon on the secondary toolbar.
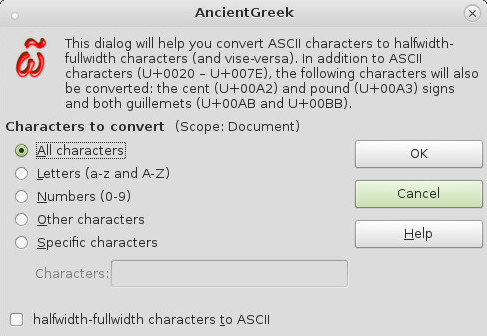
The dialog on Debian Linux
Available options:
- All characters
All the characters handled by this function: ASCII characters (U+0020 – U+007E), that is letters and numbers, quotation marks and brackets etc., plus the cent (¢ - U+00A2) and pound (£ - U+00A3) signs and both guillemots (« - U+00AB and » - U+00BB). - Letters (a-z and A-Z)
- Numbers (0-9)
- Other characters
All characters handled by this function, excluding letters and numbers. - Specific characters
When this option is selected, the "Characters" input box is enabled, making it possible to insert any character. If the conversion of any character inserted here is not possible, the character will be ignored.
When the "Halfwidth-fullwidth characters to ASCII" option is checked, a reverse conversion will be performed. This is actually redundant, since any Legacy Encoding conversion to Unicode will perform the said action by default.